Speech recognition, Speech-to-Text, Dictation, and Transcription: What’s the Difference?
Just like picking the right writing tool, choosing the right speech technology makes all the difference—here’s how to decide.


Choosing the Right Tool for the Job
A few decades ago, choosing how to write meant deciding between a pencil, a pen, or a typewriter—each suited to a different task. Today, with speech technology, we face similar choices: When should we use voice commands, live captions, dictation, or transcription?
Understanding these fundamental technologies ensures we pick the right tool for the job, whether it's issuing hands-free commands, getting accurate captions, or turning spoken words into structured text. Let’s break down the differences.
Automatic Speech Recognition (ASR) vs. Speech-to-Text: The Foundation
Speech recognition technology is everywhere, but how does it really work? To understand the difference between ASR and Speech-to-Text, we need to start with the basics—how machines process human speech and turn it into something useful.
ASR: The Technology That Listens
Automatic Speech Recognition (ASR) is the brain behind speech technology. It listens to audio, recognizes words, and converts them into text. ASR relies on:
- Acoustic models to understand sound patterns
- Language models to predict word sequences
- Machine learning to improve accuracy over time
Think of ASR as the "hearing" part of a voice assistant—it's listening, but it doesn’t always understand perfectly.
Speech-to-Text (StT): Turning ASR into Usable Text
Speech-to-Text (StT) takes ASR’s raw output and makes it usable for humans by adding:
- Punctuation and capitalization
- Better formatting
- Improved readability
ASR is the engine, Speech-to-Text is the final product.
Key Differences
| Feature | ASR (Automatic Speech Recognition) | Speech-to-Text (StT) |
|---|---|---|
| What it does | Converts speech into raw text. | Produces human-readable text. |
| Use cases | Voice assistants, search queries, live captions. | Transcription, dictation, meeting notes. |
| Output quality | May contain errors and missing punctuation. | More structured, readable text. |
Dictation vs. Transcription: Not the Same Thing
Transcribing speech and dictating text might seem similar, but they serve different purposes. Dictation is intentional speech-to-text, where the speaker controls the words and pauses for clarity. Transcription, on the other hand, captures speech as it naturally happens, often including multiple speakers and requiring post-processing.
Dictation: Talking to Your Device on Purpose
Dictation is when you speak deliberately to produce written text. You might:
- Dictate a message on your phone.
- Speak out an email.
- Use voice typing to write a report.
Dictation is structured speech-to-text—you control the words and often pause for clarity.

Transcription: Capturing Natural Speech
Transcription is more like a fly on the wall—it captures spoken words as they happen. It’s used for:
- Meetings and interviews (where multiple speakers talk naturally)
- Courtroom and medical documentation
- Podcasts and videos
Transcription often requires cleanup, such as speaker identification and punctuation.

Key Differences
| Feature | Dictation | Transcription |
|---|---|---|
| How speech is recorded | Speaker controls and dictates. | Natural speech is captured as is. |
| Editing needed? | Usually minimal. | Often requires corrections. |
| Typical users | Professionals writing reports, emails, or notes. | Journalists, researchers, and legal/medical fields. |
Live Captions: A Special Case of Transcription
Live captions are real-time transcription, but because they’re generated instantly, they prioritize speed over accuracy.
| Feature | Live Captions | Automatic Transcription |
|---|---|---|
| Speed | Instant. | Processed after recording. |
| Accuracy | Lower, due to real-time processing. | Higher, since errors can be corrected. |
| Use cases | Accessibility, live events. | Meeting transcripts, official records. |
ASR Without Text: What About Voice Commands?
Did you know not all ASR generates visible text? Many ASR-based systems never show you what they transcribe because they’re built to trigger actions instead.
Examples of ASR Without Text Output:
- Voice Assistants: "Turn off the lights" → ASR processes → Lights switch off.
- Voice Search: "Best coffee shop near me" → ASR converts speech into a search query.
- Navigation: "Take me to Central Station" → ASR processes the command → GPS system responds.
Here, ASR isn’t about producing readable text—it’s about recognizing intent.

Wrapping It Up: A Simple Hierarchy
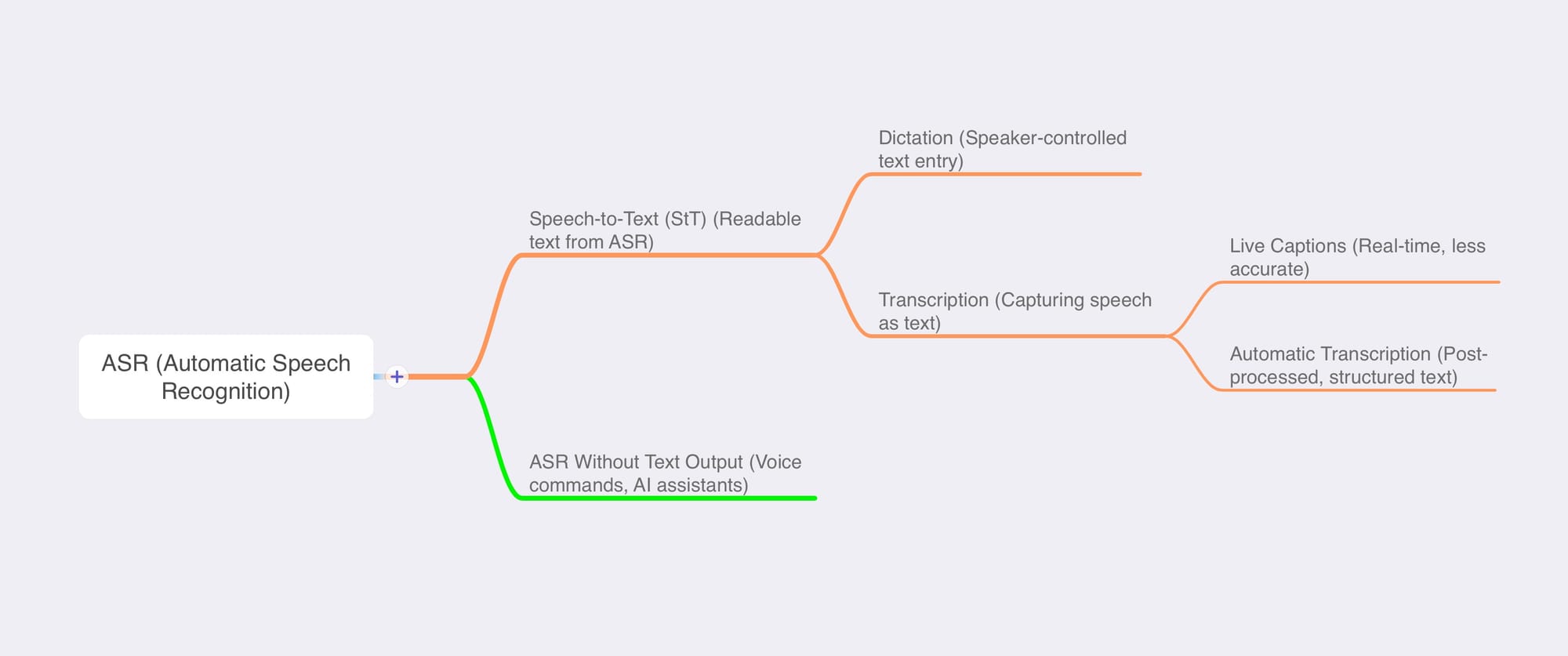
Final Takeaways
Choosing the right speech tool means understanding when to use ASR, Speech-to-Text, dictation, or transcription:
- ASR is the core technology powering speech recognition.
- Speech-to-Text makes ASR output human-readable.
- Dictation is controlled, while transcription captures free speech.
- Live captions are fast but less accurate.
- Not all ASR produces readable text—voice commands process speech without displaying it.
Understanding these distinctions helps you choose the right tool for the job, whether it’s voice-controlled automation, live captions, or structured documentation.




